.png)

.png)
Blog
min read
The Agent Security Paradox: When Trusted Commands in Cursor Become Attack Vectors
%20(1).webp)

min read
.webp)
Executive Summary
Pillar Security researchers have uncovered a critical vulnerability in Cursor (CVE-2026-22708). This technique exploits a fundamental oversight in how agentic IDEs handle shell built-in commands, allowing attackers to achieve sandbox bypass and remote code execution even when the command allowlist is empty.
By abusing implicitly trusted shell built-ins like export, typeset, and declare, threat actors can silently manipulate environment variables that subsequently poison the behavior of legitimate developer tools. This attack chain converts benign, user-approved commands—such as git branch or python3 script.py—into arbitrary code execution vectors.
Our research identified two categories of attack techniques that bypass Cursor's security controls:
One-Click Attacks require the user to approve a seemingly safe command, which then triggers malicious code due to a poisoned environment. Attackers can hijack how common developer tools display output or chain multiple environment variables to execute arbitrary code when standard tools like Git or Python run.
Zero-Click Attacks require no user interaction whatsoever. By exploiting shell syntax quirks and parameter expansion features, attackers can write malicious content to configuration files or achieve immediate code execution—all through commands that Cursor implicitly trusts and never prompts for approval.
This finding reveals that static controls like allowlists of safe commands exacerbate this risk by validating what is executed while ignoring the poisoned context in which it runs—effectively streamlining the attack by automatically approving the very commands used to trigger the payload.
What makes this attack particularly dangerous is that it exploits a paradigm shift introduced by AI agents: features that were once considered safe under human-in-the-loop assumptions become weaponizable when executed by autonomous agents that follow instructions from external content. The trust model underpinning decades of security assumptions no longer holds in agentic environments.
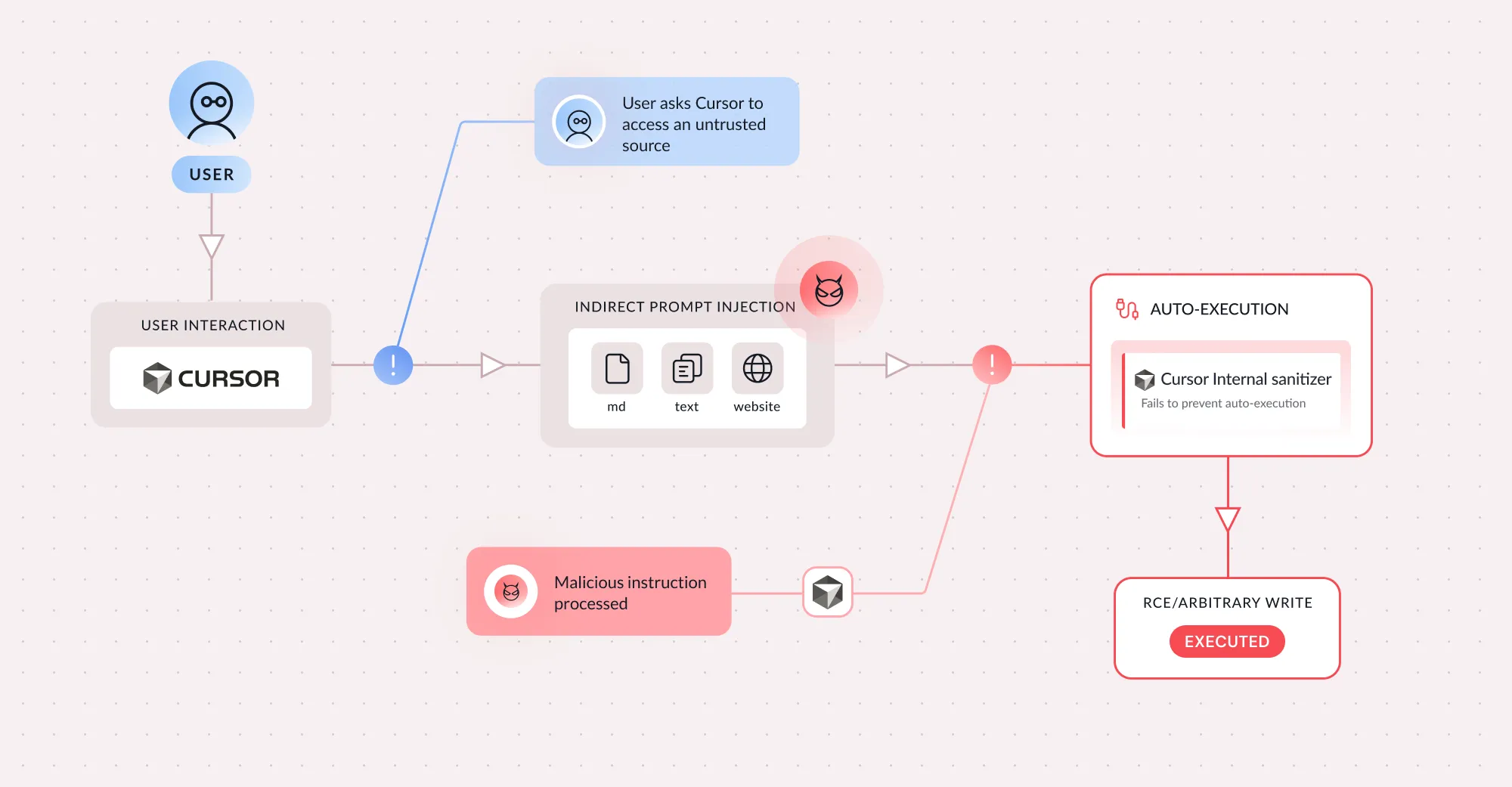
1. The Agent Security Paradox: A New Threat Model
For decades, security models have been built around a core assumption: a human is in the loop. Features like environment variables were rarely considered attack vectors because exploiting them required either physical access to the machine, social engineering a user through multiple steps, or prior compromise through another vulnerability.
Agentic IDEs break this assumption. They execute commands programmatically, unable to understand the difference between instructions and data. They follow instructions from external content such as webpages, documents, and emails, and operate with the user's or system's full privileges.
As AI agents proliferate across development tools, browsers, email clients, and operating systems, we should expect this class of vulnerability to expand. Security teams must begin auditing for features that become dangerous under autonomous execution.
The Sanitization Problem
The current security controls that exist within the industry are insufficient because they are based on content sanitization and not execution isolation. Sanitization works in the world of web exploitation because code in most cases should never be digested from user inputs, but in the world of AI-based coding applications that is not the case and thus sanitization becomes a very complex problem. The right way for the industry to move forward is to move to isolation solutions that isolate code execution and remove restrictions on the developer entirely.
2. Cursor's Security Model: The Trust Boundary
Cursor provides two protections intended to prevent autonomous execution of unapproved shell commands. The first is through a user-controlled allowlist and the second, through a server-side mechanism, where each command executed by the user is evaluated by the server that determines if the command is an actual "executable". In practice, the second control was bypassed using shell built-ins that are implicitly trusted and executed without user confirmation.
Our research demonstrates that these built-ins allow silent manipulation of environment variables, which then influence the behavior of trusted developer tools. By abusing this trust boundary, an attacker was able to convert benign, "safe" commands into arbitrary code execution—effectively achieving a sandbox bypass that leads to remote code execution.
The Core Vulnerability
Our initial finding revealed that shell built-in commands execute without user consent, even when the command allowlist is empty. These built-ins are implicitly trusted by Cursor's security model:
Even when Cursor's allowlist is empty, environment variables can still be modified without prompting the user for consent. This is due to Cursor's internal server-side command evaluator mechanism bypassing these commands and marking them as safe for execution.
3. Confirmed Attack Vectors
We identified multiple environment variable chains that lead to one-click and zero-click RCEs. The initial sandbox mitigation that the Cursor team introduced appears incomplete, addressing specific trigger paths while leaving the underlying vulnerability class exploitable.
3.1 Zero-Click Attacks
Zero-click attacks require no user interaction. They exploit shell syntax and parameter expansion features to achieve code execution or file writes through commands that Cursor never prompts for approval.
Arbitrary File Write via Export
The export command permits arbitrary file writes with attacker-controlled content. This behavior can be triggered with zero user interaction and is directly exploitable from the Composer model.
Proof of concept:
Why This Bypasses Detection:
While Cursor does attempt to sanitize the command execution input to prevent such attacks, the security sanitizer does not recognize that a here-string combined with output redirection enables arbitrary file writes without invoking a traditional command (echo, cat, etc.).
Impact:
- Appends attacker-controlled content to
~/.zshrc - Injected content executes on every new shell session
- Results in persistent code execution
Direct RCE via typeset/declare
The typeset command (alias declare) enables direct command execution by abusing zsh parameter expansion flags, without triggering any approval prompt.
Proof of concept:
Technical Breakdown:
Execution Flow:
- No variable name exists between
{(e)and:-,resulting in a null parameter - The
:-operator substitutes the default value:'$(open -a Calculator)' - The
(e)expansion flag forces evaluation after parsing - The string is executed as code
open -aCalculator runs
Impact:
- Immediate arbitrary command execution
- No user approval required
- No explicit command substitution detected by the filter
3.2 One-Click Attacks
One-click attacks require the user to approve a command that appears benign. Because the environment has been silently poisoned beforehand, the approved command triggers malicious behavior.
PAGER Hijacking (Git/Man)
Tools like git and man rely on the PAGER environment variable to determine how to display output.
Attack setup (executes without user consent):
Trigger (appears benign, may already be allowlisted):
This triggers attacker-controlled code instead of displaying output. In this example, execution of the command git branch leads to execution of arbitrary code due to an indirect prompt injection.
One might ask—"But the user is still asked to execute specific commands." While that might be true, two major risk factors remain. First, the user thinks they are being asked to run a benign command but in reality, they are executing something completely different. Second, many users add various commands to their allowlist, from git to python—in these cases the attacker will skip the human in the loop necessary to trigger the exploit.
It's worth mentioning that this path can be triggered with various environment variables such as LP_PRELOAD or GIT_ASKPASS but it requires more user interaction.
Python Warning Handler Chain
This method was found thanks to Luke Jahnke blog about Hacking with Environment Variables which really takes this exploit to the next level. Luke managed to chain a few environment variables that would lead to a potential RCE via Perl by executing a Python script. It works like this:
The PYTHONWARNINGS variable triggers Python to import the antigravity module when processing warning categories. The antigravity module is a Python Easter egg from 2008 that calls webbrowser.open() to open an xkcd comic. The webbrowser module checks the BROWSER environment variable to determine which process handles URLs (usually browsers). Setting BROWSER=perlthanks points to perlthanks, a Perl script installed by default alongside Python. The perlthanks script respects the PERL5OPT environment variable for command-line options. Finally, PERL5OPT injects arbitrary Perl code via the -M flag, achieving code execution.
If before an attacker had to have physical access to the system to make this work, and could only execute with whatever privileges the user had on the machine, in this case Cursor will be executing it using high privileges.
Attack setup (all execute without user consent):
The attacker instructs Cursor to execute the following commands. Each export is a shell built-in that executes without user consent:
Any subsequent Python script execution triggers arbitrary command execution.
For simplicity's sake, we have used the following direct prompt injection which fetches a malicious payload that will trojanize the zshrc file:
The attacker-hosted zshrc file contains the persistence payload that would lead to Calculator opening up every time the victim executes any Python script by setting up the previous exploit in the global environment variables:
Why stop here? Let’s exfiltrate id_rsa to get all the SSH keys from the user:
5. Why This Attack Is So Effective
Several factors combine to make environment variable poisoning particularly dangerous in agentic contexts.
Relying on sanitization and allow lists instead of code isolation
Allowlists and sanitizers are meant to fail. These mechanisms work quite well in web application input fields that expect benign user input, a user using a facebook as no reason to input javascript code in any field. This gets quite complicated in AI Coding agents because they expect code as input, which expands the attack surface in infinite directions thus allowing for too many command injection primitives. The right way to handle this issue is to allow full command execution to all agents in an isolated or sandbox environment and deprecate the use of allowlists completely.
Invisible Preparation, Visible Approval
The attack separates the malicious setup from the triggering action. Users see only the final command—git branch or python3 script.py—which appears completely benign. The poisoning phase happens silently through trusted built-ins that never surface for approval. This creates a fundamental asymmetry: attackers control the invisible preparation while users approve only the visible trigger.
Exploiting Existing Trust
Developers routinely allowlist common commands like git, python, or npm to reduce friction. These allow lists become attack vectors rather than security controls. The attacker doesn't need to convince the user to approve a suspicious command—they simply poison the environment and wait for the user (or the agent) to invoke something already trusted.
6. How AI Agents Changed the Threat Model
The sandbox bypass technique leverages research from Elttam's "Hacking with Environment Variables" blog post published in 2020. That research demonstrated how environment variable manipulation could achieve RCE across various scripting language interpreters.
However, the 2020 attack posed limited real-world threat because it required:
- Direct access to the victim's machine
- Ability to set multiple environment variables in sequence
- Specific interpreters (Python, Perl) already installed
- Knowledge of which variables to chain together
- Manual execution of each step
In practice, if an attacker already had that level of access, they likely had simpler paths to code execution.
AI agents eliminate these barriers entirely. They can be manipulated through prompt injection, execute commands programmatically, and chain multiple operations without human intervention. What was once a theoretical attack requiring physical access is now exploitable remotely through malicious content that an agent processes.
7. The Fix
Cursor addressed the issue by requiring explicit user approval for any commands that the server-side parser is not able to classify. However, users remain at risk when relying on predictable allowlists. To mitigate this, Cursor introduced new security guidelines that discourage allowlists.
8. Responsible Disclosure
- August 11, 2025 - Vulnerability reported to Cursor
- August 2025 - Cursor acknowledges the issue
- September 2025 - Cursor acknowledges this is a "systemic issue" with "two major initiatives underway"
- January 2026 - Cursor releases a fix, in effect closing this issue.
9. Mitigation Strategies
Treat shell built-ins (including export) as security-sensitive operations. Sandbox environment variable modifications, not just command execution. Consider environment variable isolation between agent sessions. Implement carefully curated allowlists but understand they still pose an inherent security risk, as Cursor states: “You can enable auto-approval if you accept the risk. We have an allowlist feature, but it's not a security guarantee. The allowlist is best-effort—bypasses are possible. Never use "Run Everything" mode, which skips all safety checks.”
Conclusion
The environment variable poisoning technique we have disclosed demonstrates a fundamental truth about agentic AI security: features designed for human-controlled environments become attack vectors when autonomous agents can be manipulated to exploit them.
This vulnerability required no zero-days, no memory corruption, and no complex exploitation techniques. It required only the recognition that AI agents operate under different trust assumptions than humans. By targeting the gap between Cursor's input validation and its command execution model, attackers can weaponize the developer's most trusted tools against them.
As AI assistants become deeply embedded in development workflows, the security community must evolve beyond traditional threat models. The Agent Security Paradox demands that we audit every "safe" feature for its behavior under autonomous execution - before attackers do it for us.
FAQs
What is CVE-2026-22708 and how does it affect Cursor's security model?
CVE-2026-22708 is a sandbox bypass vulnerability in Cursor, the agentic IDE, that allows remote code execution even when the command allowlist is empty. It exploits shell built-in commands like export, typeset, and declare, which Cursor's server-side evaluator implicitly trusts and executes without user approval, enabling silent environment variable poisoning.
How do zero-click attacks work in Cursor's agentic environment without any user interaction?
Zero-click attacks in Cursor exploit shell syntax and parameter expansion to achieve code execution or arbitrary file writes through commands the IDE never prompts users to approve. For example, the typeset command abuses zsh's expansion flag to force evaluation of embedded command substitution, executing arbitrary code with no approval prompt and no explicit command substitution detectable by the sanitization filter.
Why do command allowlists in agentic IDEs like Cursor make environment variable poisoning attacks more dangerous?
Allowlists increase risk because they validate what is executed while ignoring the poisoned context in which execution happens. Developers routinely allowlist commands like git or python3 to reduce friction, which attackers exploit by silently poisoning the environment first and then waiting for a trusted, already-approved command to trigger the malicious payload automatically.
How did AI agents change the real-world exploitability of environment variable poisoning attacks that were documented as far back as 2020?
The 2020 Elttam research on environment variable RCE required direct machine access, manual execution of multiple steps, and specific interpreters already installed — making it largely theoretical. AI agents eliminate every one of these barriers: they accept instructions from external content via prompt injection, chain environment variable assignments programmatically, and execute without human intervention, turning a physical-access-only attack into a fully remote exploit.
What is the recommended mitigation approach for environment variable poisoning in agentic IDE security?
Pillar Security's researchers argue that sanitization and allowlists are fundamentally insufficient because they validate commands while ignoring execution context. The recommended approach is full execution isolation — sandboxing the entire command execution environment, including environment variable modifications, and isolating environments between agent sessions rather than relying on allowlists that the research demonstrates can be bypassed.
Subscribe and get the latest security updates
Back to blog


.webp)

%20(1).png)
%20(1).webp)


