Why Red Team AI
When AI models transition from the controlled laboratories of LLM providers into real‑world business applications, their attack surface expands dramatically. In production, a model is no longer shielded by a clean test harness; it must process free‑form user inputs, call third‑party APIs, query legacy databases and operate within complex pipelines. Each integration point becomes a potential entry vector that was never exposed during development.
The true vulnerability landscape only emerges when these models are embedded into specific use cases. In an enterprise setting, a single AI service may sit between untrusted external content, sensitive internal data and a constellation of tools — creating numerous entry points for prompt‑injection, data‑poisoning and tool‑misuse attacks. Current security tools and pen‑testing methodologies were built for deterministic software and cannot reliably detect or reproduce AI‑specific failures. Compounding the challenge, regulatory frameworks (e.g., GDPR, HIPAA) impose strict requirements on how personal data is processed and tested.
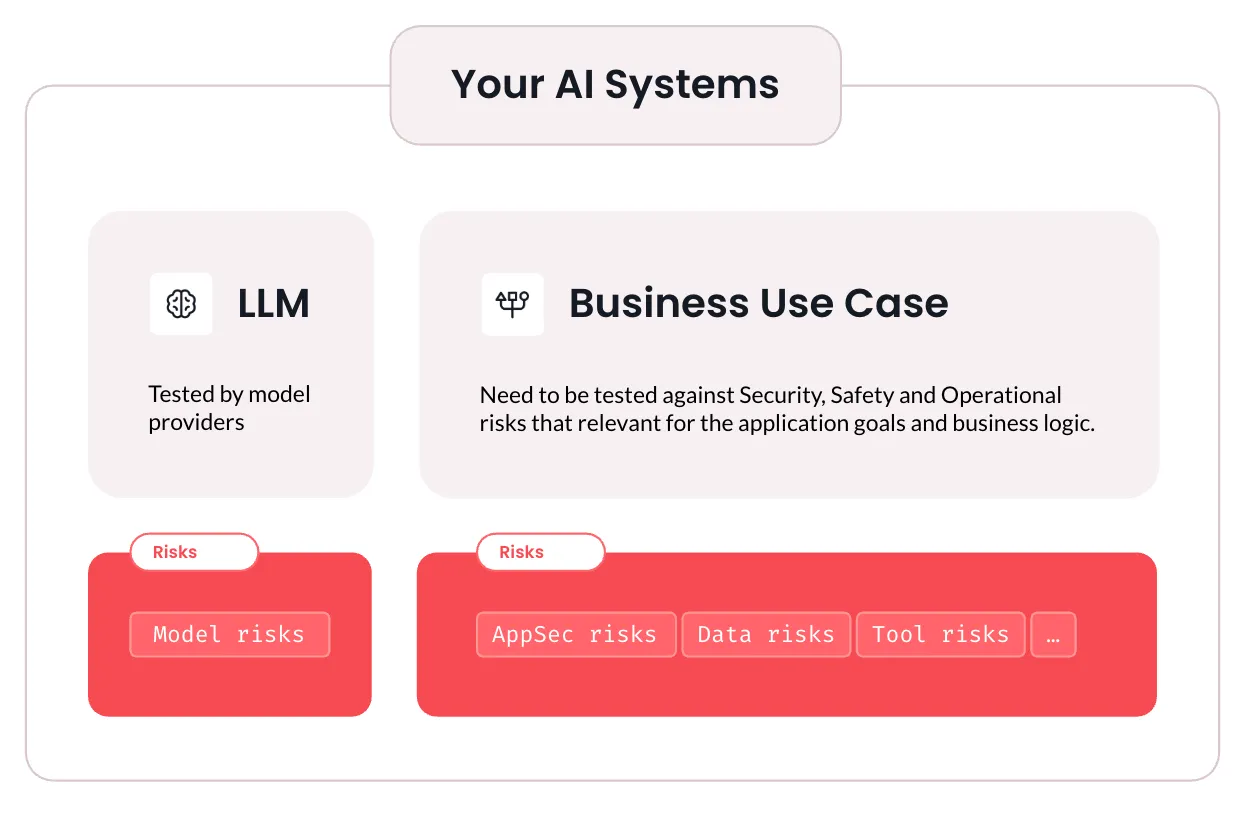
AI red‑teaming fills this gap. It treats the entire AI system - model, application code, data flows and tool integrations - as the attack surface. By simulating realistic attack scenarios and probing the system end‑to‑end, red‑teamers can uncover model risks, application‑security flaws, data‑exfiltration paths and tool‑hijack chains. This structured approach ensures that business use cases are tested against the security, safety and operational risks relevant to their goals and logic, giving organisations a clear roadmap to mitigate new risks and comply with evolving regulations.